
2級 対策テキスト&問題集 公式ページ")
ビールの成分データでクラスター分析を学ぶ
2017/08/01
カテゴリ:エンタメ
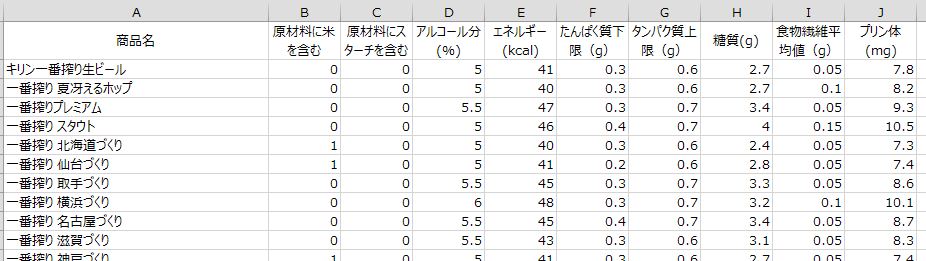
今日から8月ということで、夏真っ盛りです。こんなときは冷たいビール!ということで、ビールのデータを使って「クラスター分析」の解説をします。データはキリンビールのこちらのサイトに掲載されているデータを使用し、各ビールの栄養成分がどのくらい類似しているのかを分析してみました。
まず、データを加工します。データの加工はすべてExcelで行いました。「原材料に米を含む」と「原材料にスターチを含む」は1/0のデータとし、該当する場合を1としました。タンパク質は「0.3~0.6」のような記載だったので、下限「0.3」と上限「0.6]のようにデータを分けました。食物繊維は下限と上限の平均値を取りました。
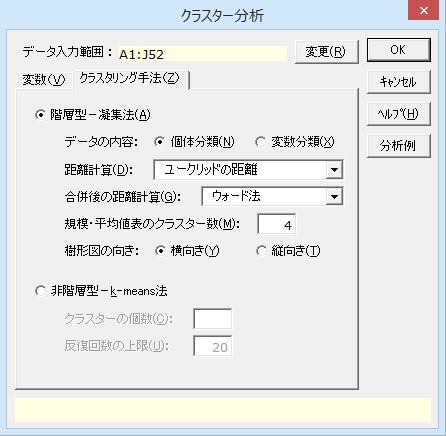
クラスター分析には「階層型」と「非階層型」があります。エクセル統計の「クラスター分析」をクリックすると、ダイアログの「クラスタリング手法」のタブの中に「階層型-凝集法」「非階層型-k-means法」の2つの手法があることが分かります。「非階層型」の方は「k-means法」という名前でもよく知られています。
階層型について
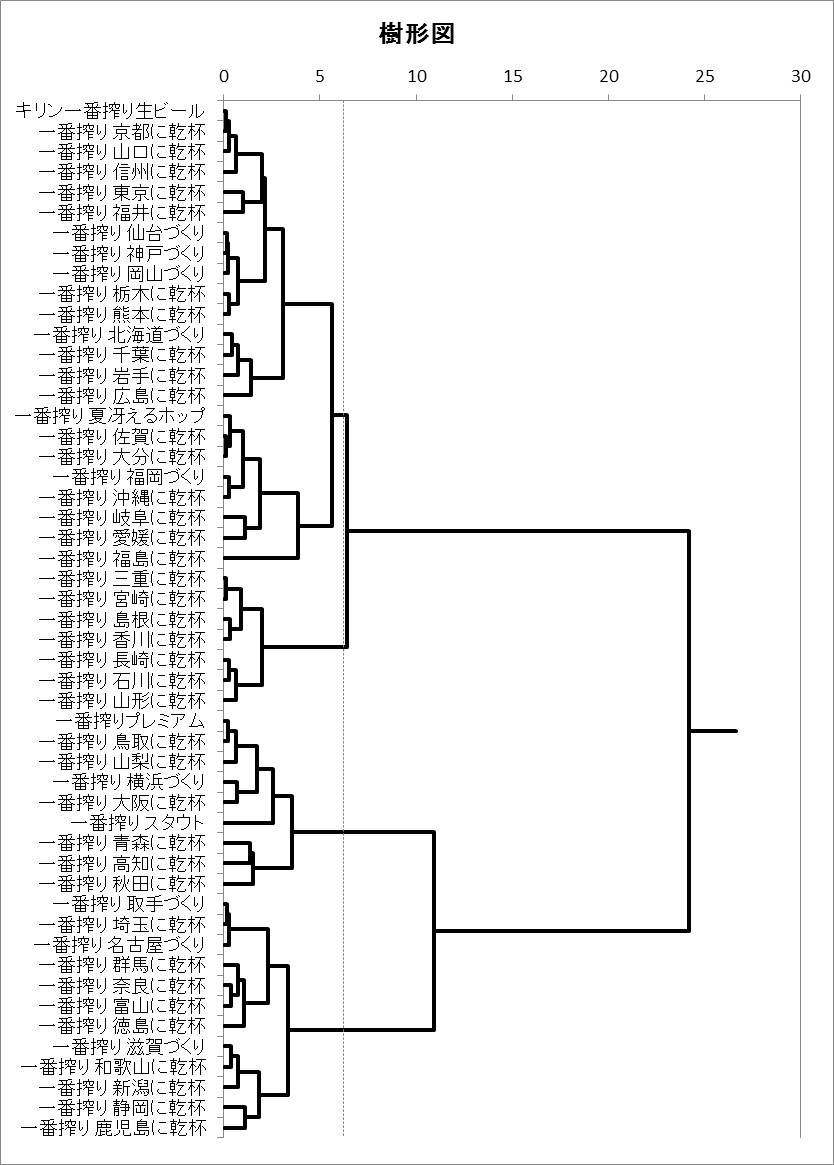
「階層型」は、データの類似性が高いものどうしを順にくっつけていく分析方法です。くっついていく途中過程を「デンドログラム(樹形図)」というトーナメント表のようなグラフで見ることができます。ビールのデータの場合このようなデンドログラムになりました。このデンドログラムは縦型ですが、エクセル統計ではオプションの設定により縦型も横型もどちらも出力することができます。
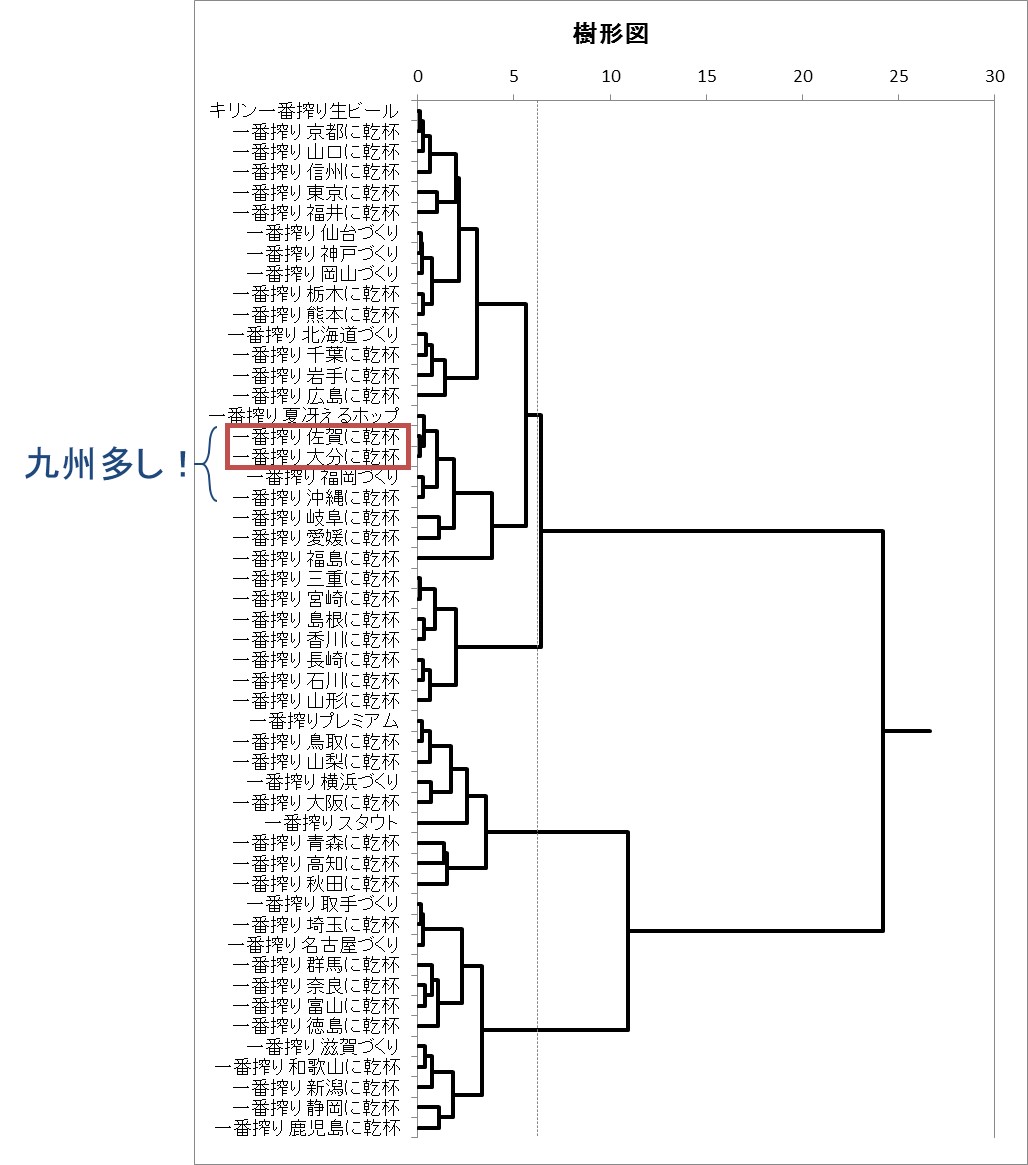
例えば、一番搾り佐賀に乾杯と大分に乾杯は非常に類似性が高く、またこの近辺には福岡づくりや沖縄に乾杯など九州のビールが固まっていることが分かります。製品名の横にある線の長さが製品間の距離(=短い=類似性が高い)を表します。
ちなみに、縦の点線は「4つのクラスターに分けるならここですよ」という印です。この解析では4つにしてみましたが、この値は自由に設定することができます。
非階層型について
「非階層型(k-means法とも呼ばれます)」ははじめにいくつのグループに分けたいかを設定します。次に、各データにランダムにグループを割り当てます(データ1はグループ4など)。グループ毎に重心を計算し、各データに割り当てられたグループを、各データから最も近い重心のグループに変更します。これを何回か繰り返し、変化がなくなったら終了するというものです。ここでグループと書いていたものが「クラスター」のことです。
「階層型」と異なり、データをまとめる過程は出力されません。こちらはエクセル統計の出力ですが、このように各データがどのクラスターに割り当てられたかという結果が出力されます。
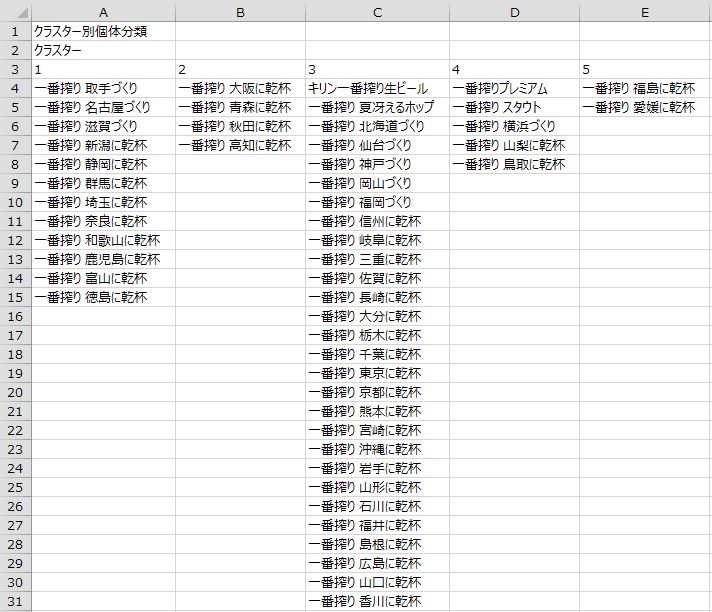
まとめ
クラスター分析には大きく分けると2つの方法があり、計算方法が異なるためにクラスタリング結果は必ずしも一致しません。そしてさらに「階層型」の中にも、データの類似性を計算するための方法が複数種類あります。
どの手法を使えばいいのか、については最善解はありません。データの性質や、それぞれ手法のの特性、メリット・デメリットを理解して使います。例えば「階層型」の場合データがまとまる過程を見ることができますが、計算量が多いため大きなデータに対しては不向きです。データが大きい場合には「非階層型」の方がよく使われる傾向にあります。



