
2級 対策テキスト&問題集 公式ページ")
- Step1. 基礎編
- 23. 検定の前に
23-5. 検定統計量と棄却域・採択域
■検定統計量
身長や体重などについて検定を行う場合は、コインの裏表が出る確率とは異なり、取りうる値がどのくらいの確率でその値となるかが分かりません。そこで、身長や体重の値を「検定するための値」に変換します。このようにして算出された値が検定統計量(統計量と呼ばれることもあります)となります。
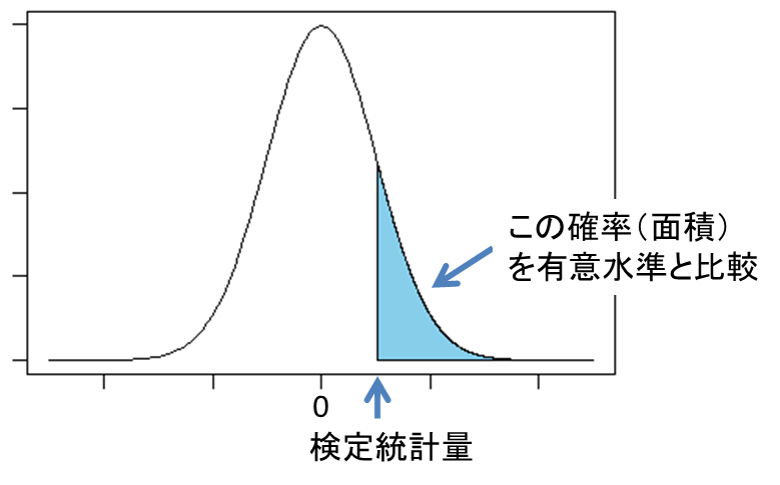
検定では、データから算出された検定統計量より極端な値をとる確率が有意水準と比較して大きいのか、小さいのかに基づいて帰無仮説を棄却するかどうかを判断します。検定統計量にはいくつかの種類がありますが、ここでは代表的な2つについて説明します。
1. 統計量z(=z値)
平均が0、分散が1となるようにデータを標準化した値のことです。例えば標本平均を標準化した値は次の式から算出できます( :データの平均、
:データの平均、 :母平均、
:母平均、 :母分散、
:母分散、 :サンプルサイズ)。分母の
:サンプルサイズ)。分母の は標本平均の標準誤差=標本平均の標準偏差を表します。統計量zは標準正規分布に従うため、統計量zを用いた検定を行う際には標準正規分布を使います。
は標本平均の標準誤差=標本平均の標準偏差を表します。統計量zは標準正規分布に従うため、統計量zを用いた検定を行う際には標準正規分布を使います。

2. 統計量t(=t値)
20-1章で既に学びましたが、次の式から算出される値のことです( :不偏分散)。サンプルサイズがnの場合、統計量tは自由度
:不偏分散)。サンプルサイズがnの場合、統計量tは自由度 のt分布に従います。そのため、統計量tを用いた検定を行う際には自由度のt分布を使います。統計量tを用いた検定のことを「t検定」といいます。t検定は、調べる値の母集団が正規分布することが前提条件となります。
のt分布に従います。そのため、統計量tを用いた検定を行う際には自由度のt分布を使います。統計量tを用いた検定のことを「t検定」といいます。t検定は、調べる値の母集団が正規分布することが前提条件となります。

例題:
日本人の男性100人をランダムに選び、その身長を測定したところ平均 、不偏分散
、不偏分散 となりました。身長の分布は正規分布に従うとする時、日本人の男性の平均身長は180cmと言ってよいでしょうか。
となりました。身長の分布は正規分布に従うとする時、日本人の男性の平均身長は180cmと言ってよいでしょうか。
この場合の帰無仮説 は「日本人の男性の平均身長は180cmである」、対立仮説
は「日本人の男性の平均身長は180cmである」、対立仮説 は「日本人の男性の平均身長は180cmではない」となります。この例題では母分散は分からないので、標本から得られた不偏分散を使って統計量tを求めます。
は「日本人の男性の平均身長は180cmではない」となります。この例題では母分散は分からないので、標本から得られた不偏分散を使って統計量tを求めます。

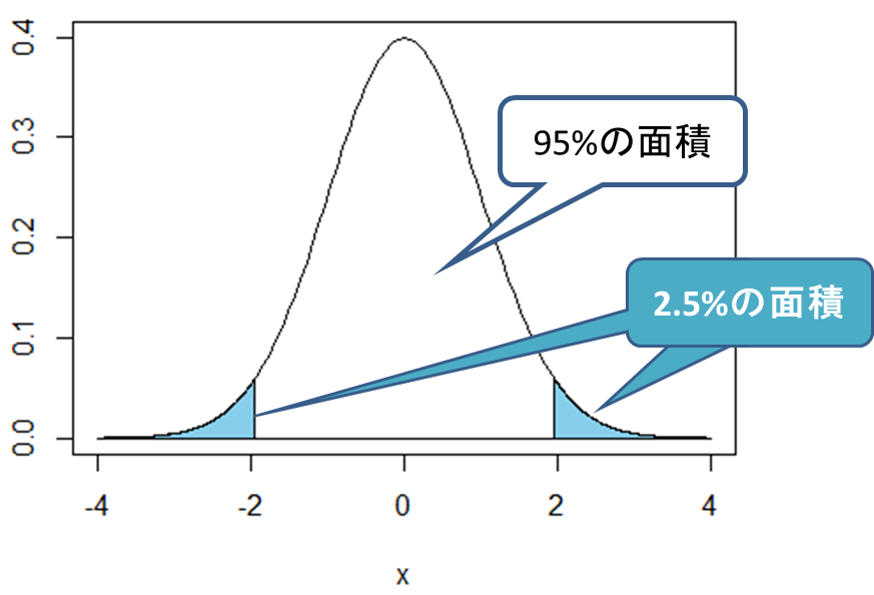
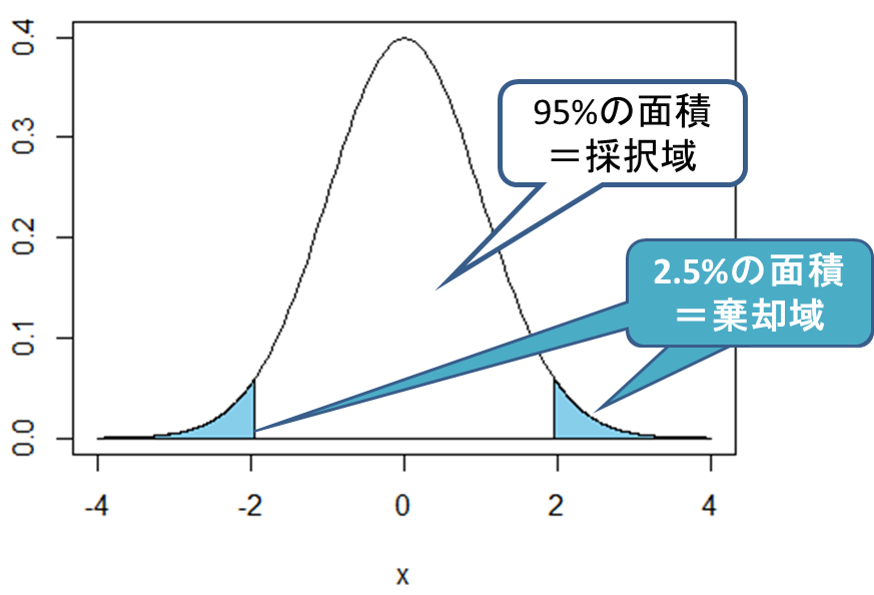
この統計量tを用いて検定を行います。有意水準5%で検定する時、統計量tが次の図のt分布の水色部分に入る場合に帰無仮説は棄却されます。両端の水色部分の面積は合わせると全体の5%であり、統計量tがこの部分に入るということは5%以下でしか起こらない極めて珍しい事象であると判定されます。
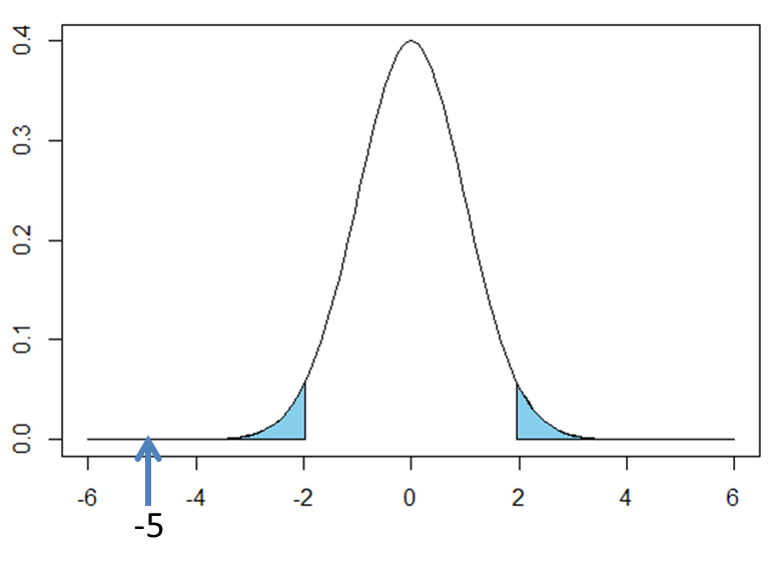
この例題では統計量t=-5となり、この値は上図の左側の水色部分に含まれるため、有意水準5%では帰無仮説は棄却され、対立仮説が採択されます。つまり、「日本人の男性の平均身長は180cmではない」と結論づけられます。
■棄却域と採択域
上図の例で、水色の部分は帰無仮説が棄却される領域であることから「棄却域」と呼ばれます。反対に、白色の部分は帰無仮説が棄却されない領域であることから「採択域」と呼ばれます。
■おすすめ書籍
統計を多変量解析も含めて一通り学ぶには最適です。数式を多用していないので読みやすいですし、イラストも多めなので飽きません。実験計画法、ノンパラ、因子分析・主成分分析まで盛り込まれているとても贅沢な1冊です。最大のポイントは、統計手法の説明に我らがエクセル統計を用いている点です!!

23. 検定の前に
事前に読むと理解が深まる- 学習内容が難しかった方に -
- 20. 母平均の区間推定(母分散未知)
20-1. 標本とt分布
- 20. 母平均の区間推定(母分散未知)
20-2. t分布表
- ブログ
よくある間違い
- ブログ
p値と有意水準
- ブログ
P = 0.05 だったら


