
2級 対策テキスト&問題集 公式ページ")
- Excelノート
- 統計検定 データサイエンス基礎のための分析ツールの使い方
2-4. 分析ツール 分散分析:一元配置、二元配置
この章では分析ツールの分散分析について説明します。下記のリンクからそれぞれの解説に飛ぶことができます。
分散分析のまとめ
| 分析ツール名 | 使い方 | 関連リンク |
|---|---|---|
| 分散分析:一元配置 | 1つの因子に含まれる水準間の平均値の差を見るための方法。 例えば、ある学校の1組、2組、3組の算数のテストのデータがある場合、一元配置分散分析を用いて、1組、2組、3組の算数のテストの平均点に差があるかどうかを検定できる。 | 29-2. 一元配置分散分析の流れ1 |
| 分散分析:繰り返しのある二元配置 | 2つの因子における水準間の平均値の差を見るための方法。 また、2つの因子が組み合わさることで現れる相乗効果(交互作用)の有無の確認もできる。 例えば、薬A、B、Cをそれぞれ10mg、20mg投与した場合の効果について、それぞれのカテゴリーのデータが複数個ある場合、繰り返しのある二元配置分散分析を用いて薬の種類によって得られる平均値に差があるか、あるいは薬の投与量によって得られる平均値に差があるかどうかを検定できる。 | 30-1. 二元配置分散分析の分散分析表1 |
| 分散分析:繰り返しのない二元配置 | 「繰り返しのある二元配置」と同じ。 ただし、交互作用の解析はできない。 例えば、薬A、B、Cをそれぞれ10mg、20mg投与した場合の効果について、それぞれのカテゴリーのデータが1個ずつある場合、繰り返しのない二元配置分散分析を用いて薬の種類によって得られる平均値に差があるか、あるいは薬の投与量によって得られる平均値に差があるかどうかを検定できる。 | 30-1. 二元配置分散分析の分散分析表1 |
分散分析:一元配置
次のデータは「一元配置分散分析─エクセル統計による解析事例」に掲載しているマウスの食餌摂取量と成長のとの関係についてのデータです。このデータを使って「一元配置分散分析」を行ってみます。
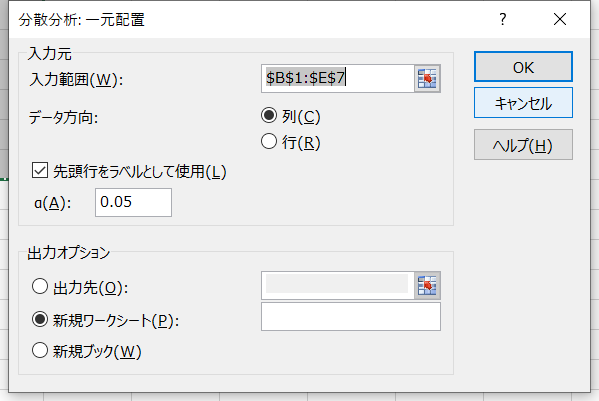
分析ツールから「分散分析:一元配置」を選択し、ウィンドウを次のように設定します。
【オプションの説明】
- 入力範囲:データの範囲
- データ方向:データが縦に並んでいる場合は「列」を、横に並んでいる場合は「行」を選択
- 先頭行をラベルとして使用:入力範囲にラベル(列名)を含む場合はチェックする
- α:有意水準(F境界値に反映される)
- 出力先:指定したセルに結果を出力する場合に使用
- 新規ワークシート:新規ワークシートに結果を出力する場合に使用
- 新規ブック:新規ブックに結果を出力する場合に使用
すると、一元配置分散分析の結果が表示されます。
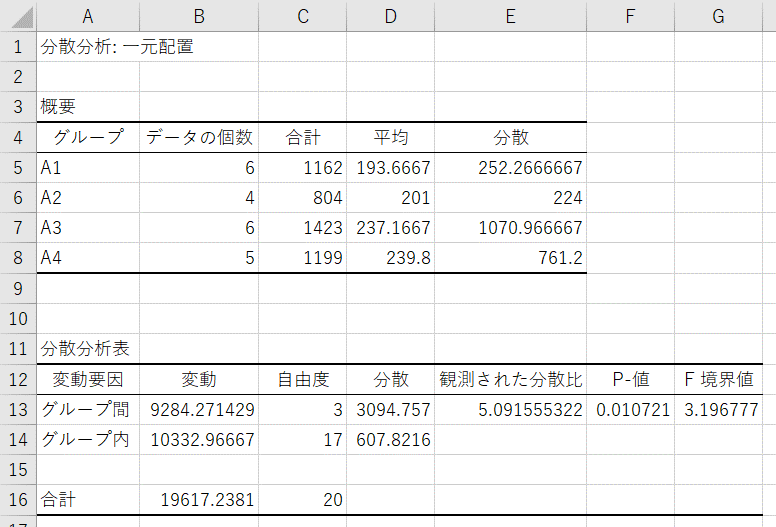
【結果の説明(概要)】
- データの個数:各グループのデータの数。
- 合計:各グループのデータの値の合計値。
- 平均:各グループのデータの値の平均値。一元配置分散分析ではこの平均値に差があるかどうかを検定する。
- 分散:各グループのデータの値の不偏分散。
【結果の説明(分散分析表)】
- 変動:グループ間の平方和、グループ内(=残差)の平方和、合計(=全体)の平方和(=グループ間の平方和+残差の平方和)
- 自由度:グループ間の自由度(グループの数-1)、残差の自由度(全体の自由度-グループ間の自由度)、全体の自由度(全データ数-1)
- 分散:変動を自由度で割ったもの
- 観測された分散比:グループ間の分散を残差の分散で割ったもの
- P-値:観測された分散比を元にF検定した結果
- F境界値:F検定に使用したF分布における棄却限界値
分散分析:繰り返しのある二元配置
次のデータは「30-1. 二元配置分散分析の分散分析表1」に掲載しているある作物の収量についてのデータです。このデータを使って「繰り返しのある二元配置分散分析」を行ってみます。
「繰り返しのある」とは、同一カテゴリー(このデータの場合、例えば土A・肥料100g)に属するデータが複数(このデータの場合3つ)あるものを指します。もし、同一カテゴリーに属するデータが1つしかない場合には、「分散分析:繰り返しのない二元配置」を使います。
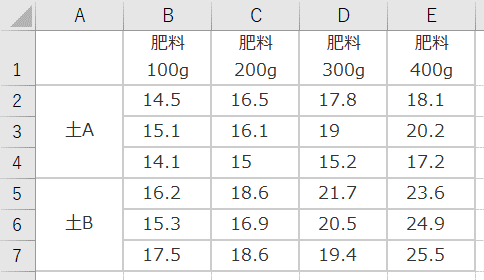
※ここでは、「A2、A3、A4のセル(土A)」および「A5、A6、A7(土B)」のセルを結合してデータを見やすくしていますが、セルを結合していないデータのままでも問題なく解析できます。
分析ツールから「分散分析:繰り返しのある二元配置」を選択し、ウィンドウを次のように設定します。
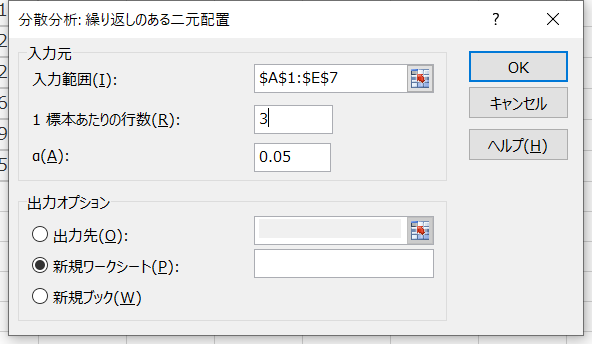
【オプションの説明】
- 入力範囲:データの範囲(データの中に、行ラベルと列ラベルを含める必要がある)
- 1標本あたりの行数:1つのカテゴリーに含まれるデータの数
- α:有意水準(F境界値に反映される)
- 出力先:指定したセルに結果を出力する場合に使用
- 新規ワークシート:新規ワークシートに結果を出力する場合に使用
- 新規ブック:新規ブックに結果を出力する場合に使用
すると、二元配置分散分析の結果が表示されます。
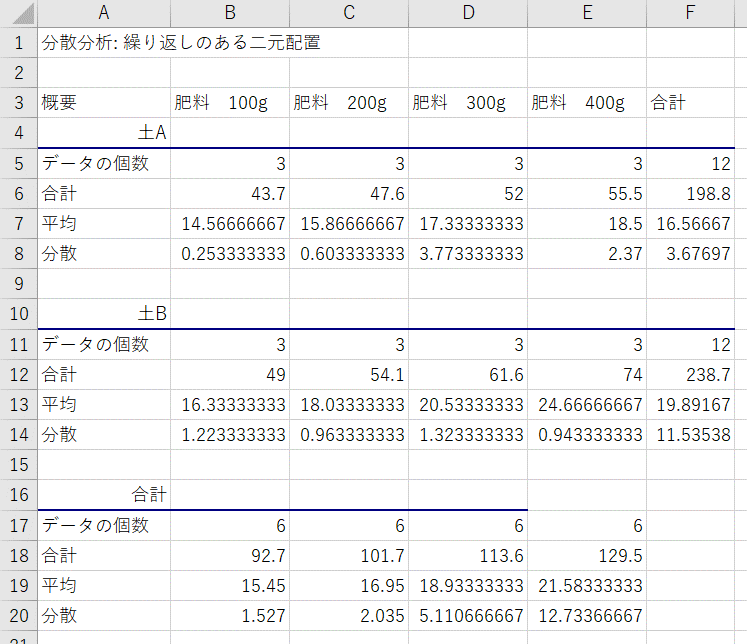
【結果の説明(概要)】
- データの個数:各カテゴリー/各水準(土・肥料)におけるデータの数。
- 合計:各カテゴリー/各水準(土・肥料)におけるデータの値の合計値。
- 平均:各カテゴリー/各水準(土・肥料)におけるデータの値の平均値。二元配置分散分析では各水準の平均値に差があるかどうかを検定する。
- 分散:各カテゴリー/各水準(土・肥料)におけるデータの値の不偏分散。
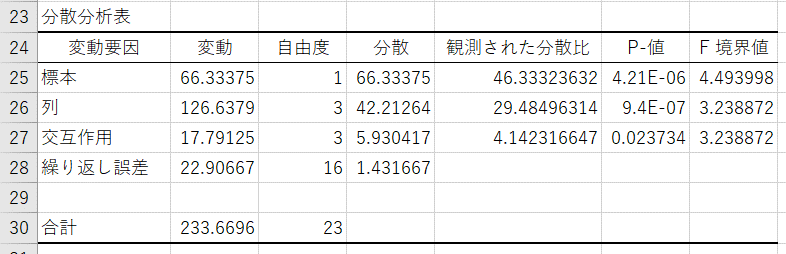
【結果の説明(分散分析表)】
- 変動:標本(土)の平方和、列(肥料)の平方和、交互作用(土×肥料)の平方和、繰り返し誤差(=残差)の平方和、合計(=全体)の平方和(=すべての平方和の総和)
- 自由度:標本の自由度(標本の数-1)、列の自由度(列の数-1)、交互作用の自由度((標本の数-1)×(列の数-1))、残差の自由度(全体の自由度-標本、列、交互作用の自由度)、全体の自由度(全データ数-1)
- 分散:変動を自由度で割ったもの
- 観測された分散比:グループ間の分散を残差の分散で割ったもの
- P-値:観測された分散比を元にF検定した結果
- F境界値:F検定に使用したF分布における棄却限界値
分散分析:繰り返しのない二元配置
次のデータは「繰り返しのある二元配置分散分析」で使ったデータを、繰り返しのないデータに加工したものです。このデータを使って「繰り返しのない二元配置分散分析」を行ってみます。
「繰り返しのない」とは、同一カテゴリー(このデータの場合、例えば土A・肥料100g)に属するデータが1つしか無いものを指します。
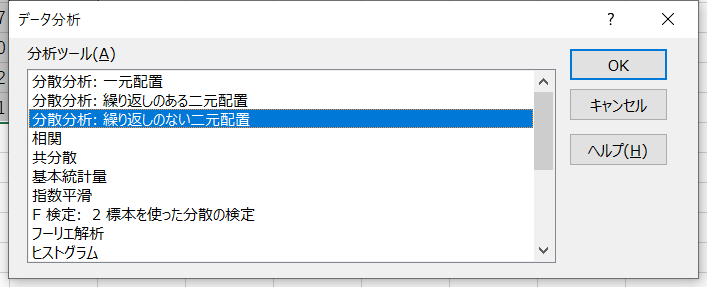
分析ツールから「分散分析:繰り返しのない二元配置」を選択し、ウィンドウを次のように設定します。
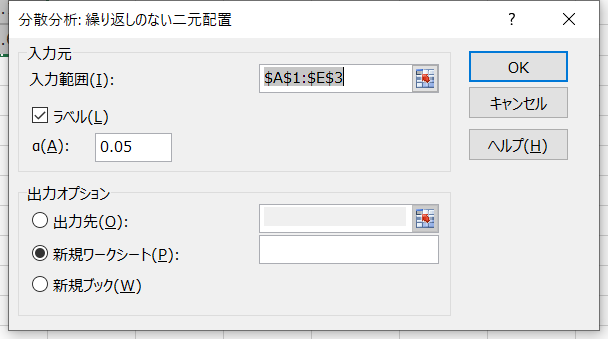
【オプションの説明】
- 入力範囲:データの範囲(データの中に、行ラベルと列ラベルを含める必要がある)
- ラベル:入力範囲にラベル(行名および列名)を含む場合はチェックする
- α:有意水準(F境界値に反映される)
- 出力先:指定したセルに結果を出力する場合に使用
- 新規ワークシート:新規ワークシートに結果を出力する場合に使用
- 新規ブック:新規ブックに結果を出力する場合に使用
すると、二元配置分散分析の結果が表示されます。
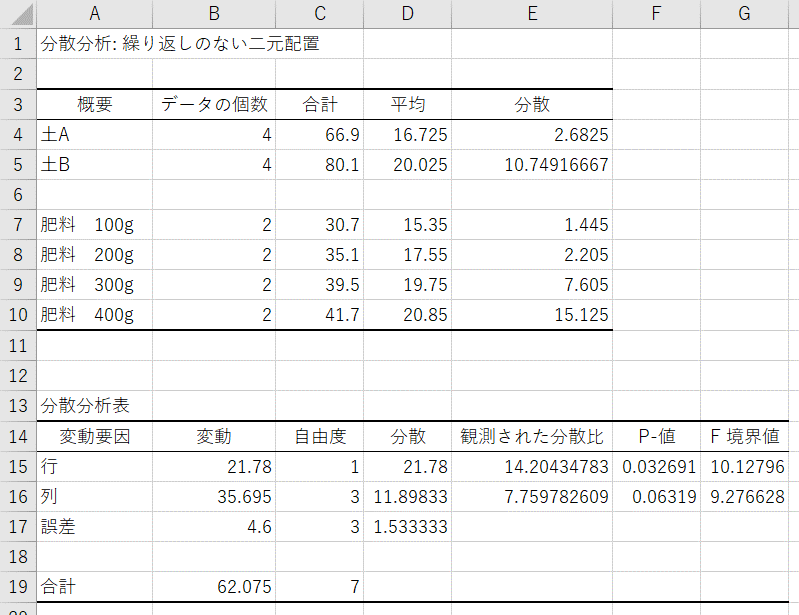
【結果の説明(概要)】
- データの個数:各グループのデータの数。
- 合計:各カテゴリー/各水準(土・肥料)におけるデータの値の合計値。
- 平均:各カテゴリー/各水準(土・肥料)におけるデータの値の平均値。二元配置分散分析では各水準の平均値に差があるかどうかを検定する。
- 分散:各カテゴリー/各水準(土・肥料)におけるデータの値の不偏分散。
【結果の説明(分散分析表)】
- 変動:行(土)の平方和、列(肥料)の平方和、誤差(=残差)の平方和、合計(=全体)の平方和(すべての平方和の総和)
- 自由度:標本の自由度(行の数-1)、列の自由度(列の数-1)、残差の自由度(全体の自由度-行、列の自由度)、全体の自由度(全データ数-1)
- 分散:変動を自由度で割ったもの
- 観測された分散比:グループ間の分散を残差の分散で割ったもの
- P-値:観測された分散比を元にF検定した結果
- F境界値:F検定に使用したF分布における棄却限界値
統計検定 データサイエンス基礎のための分析ツールの使い方
- 2-1. 分析ツール t検定・z検定
- 2-2. 分析ツール 基本統計・相関・ヒストグラム
- 2-3. 分析ツール 回帰分析
- 2-4. 分析ツール 分散分析:一元配置、二元配置
- 2-5. 分析ツール 乱数発生・順位と百分位数・サンプリング


