
2級 対策テキスト&問題集 公式ページ")
- Step2. 中級編
- 1. 2×2のクロス集計表と様々な比率
1-2. 検査精度の信頼区間
2×2のクロス集計表から得られた値に対する信頼区間の求め方は、「母比率の信頼区間の求め方」で学んだ方法と同じです。母比率pの95%信頼区間は次の式から求められます。

この式を見ても分かる通り、サンプルサイズが多いほど95%信頼区間の幅は狭くなります。この式を使って、次のようなデータから「感度」と「特異度」の信頼区間を求めてみます。
| 罹患している | 罹患していない | |
|---|---|---|
| 検査陽性(+) | 95 | 3 |
| 検査陰性(-) | 5 | 97 |
■感度:0.95


■特異度:0.97


上の式は、「サンプルサイズがある程度大きい場合(目安はnp>5、およびn(1-p)>5と言われています)、二項分布 は正規分布
は正規分布 に近似できるという定理(ラプラスの定理)」を利用しています。したがって、サンプルサイズが十分に大きくない場合や、標本比率(ここでは感度や特異度)が0や1に近い場合には次の式が用いられる場合があります。nはサンプルサイズ、xはあるイベントの発生回数を表します。
に近似できるという定理(ラプラスの定理)」を利用しています。したがって、サンプルサイズが十分に大きくない場合や、標本比率(ここでは感度や特異度)が0や1に近い場合には次の式が用いられる場合があります。nはサンプルサイズ、xはあるイベントの発生回数を表します。

ただし信頼区間の下限値は、次の式から

信頼区間の上限値は次の式から求めます。

この式は「ClopperとPearsonの正確信頼区間」と呼ばれ、F分布を使って信頼区間を算出します。この式を使って感度と特異度の95%信頼区間を算出すると、次のようになります。
■感度:0.95
n=100、x=95を代入

■特異度:0.97
n=100、x=97を代入

母比率の信頼区間を求める公式は上に挙げた2つ以外にもいくつかの手法があります。エクセル統計には合計5つの手法が搭載されています。
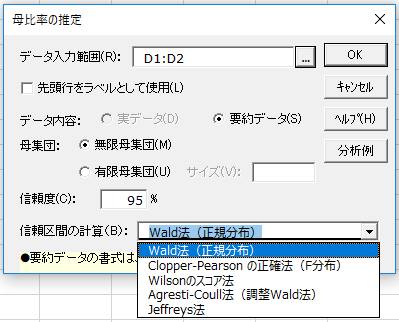
また、陽性尤度比と陰性尤度比の95%信頼区間は次の式から算出します。指数関数を使う点がポイントです。
| 罹患している | 罹患していない | 合計 | |
|---|---|---|---|
| 検査陽性(+) | a | b | a+b |
| 検査陰性(-) | c | d | c+d |
| 合計 | a+c | b+d | a+b+c+d |
■陽性尤度比:{a/(a+c)}/{b/(b+d)}=感度/{1-特異度}=感度/偽陽性率
![\displaystyle \exp \left[\ln\left(\frac{sensitivity}{1-specificity}\right)\pm 1.96 \sqrt{-\frac{1-sensitivity}{a}+\frac{specificity}{b}} \right]](https://bellcurve.jp/statistics/wp-content/ql-cache/quicklatex.com-070b5a004e9c9785058b5e3069dfb5aa_l3.png "Rendered by QuickLaTeX.com")
■陰性尤度比:{c/(a+c)}/{d/(b+d)}={1-感度}/特異度=偽陰性率/特異度
![\displaystyle \exp \left[\ln\left(\frac{1-sensitivity}{specificity}\right)\pm 1.96 \sqrt{\frac{sensitivity}{c}+\frac{1-specificity}{d}} \right]](https://bellcurve.jp/statistics/wp-content/ql-cache/quicklatex.com-f8c60ec4d7c98a7cecb58dae9a084225_l3.png "Rendered by QuickLaTeX.com")


