2級 対策テキスト&問題集 公式ページ")
- Step3. 実践編
- 1. データの整理と可視化
1-3. 基本統計量とヒストグラム
次のデータは、「Step0. 初級編 1-1. データをとってみよう」で用いたデータです。このデータを使って、基本統計量の計算とヒストグラムの作成を行ってみましょう。
ファイルのダウンロードはこちらから
- (日本語)neko_1nensei.csv
- (英語)neko_1nensei_eng.csv
■Excelによる解析例
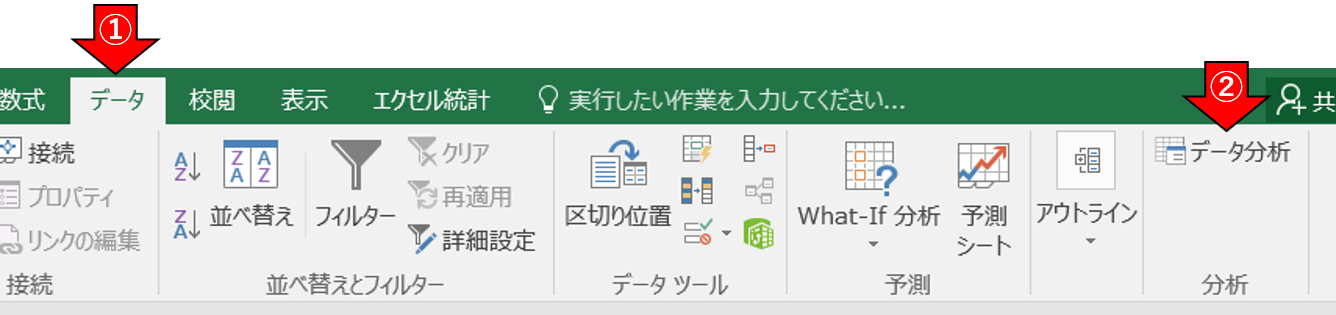
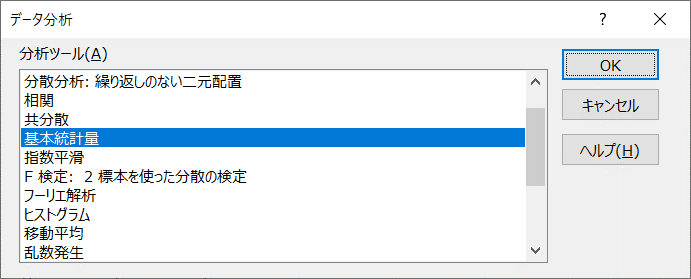
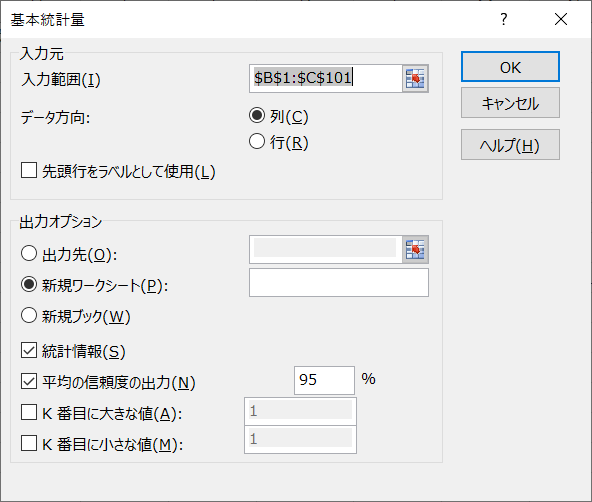
- データ > データ分析 > 基本統計量を選択
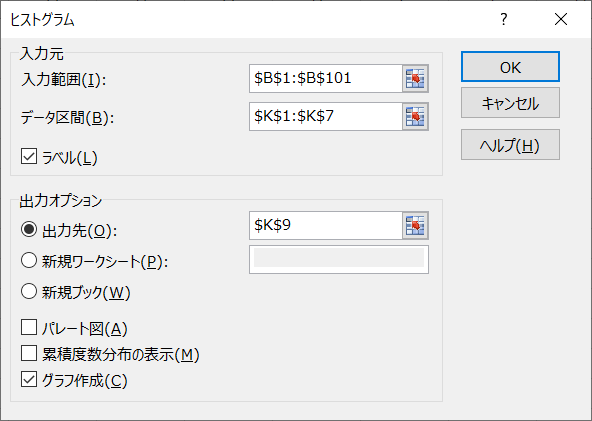
- 「入力元」と「出力オプション」を図のように設定 > [OK]をクリック
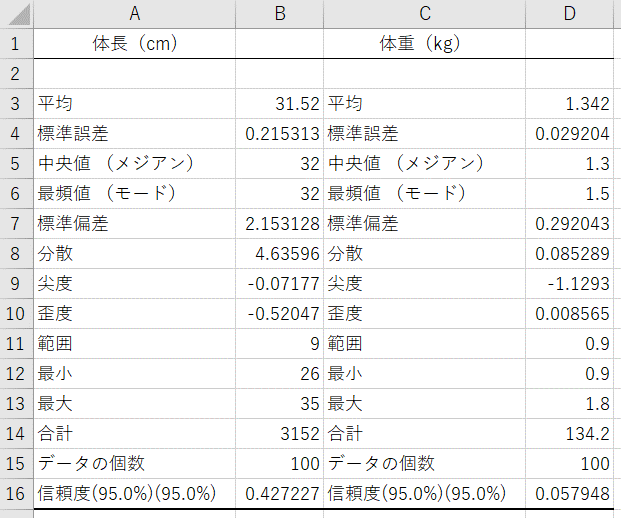
- 基本統計量が出力される
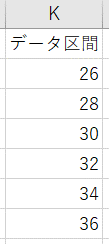
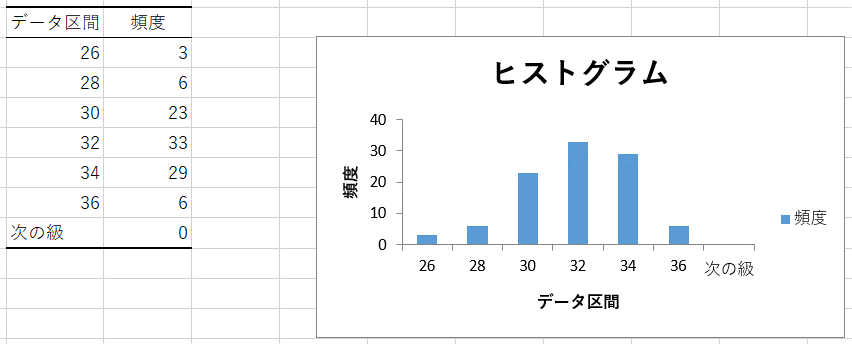
- 「体長」のヒストグラムを作成するためのデータ区間を作成
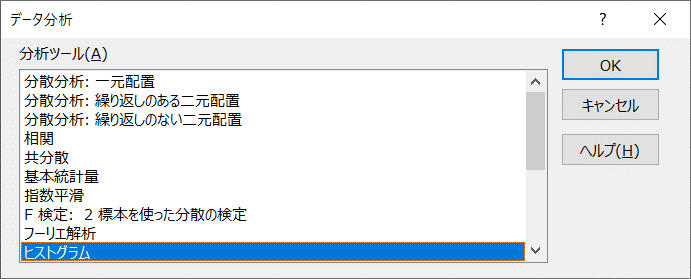
- データ > データ分析 > ヒストグラムを選択
- 「入力元」と「出力オプション」を図のように設定 > [OK]をクリック
- デフォルトのヒストグラムが出力される
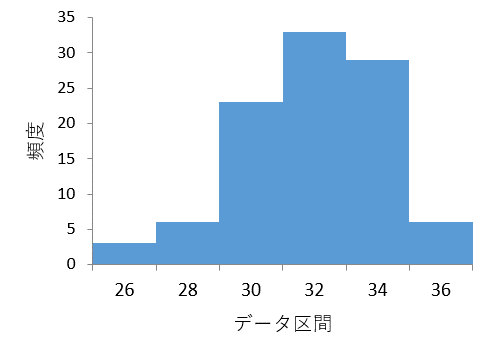
- デフォルトのグラフを加工
※「データ分析」が見当たらない方はこちらを参考に設定を行ってください。
※ここでは2cm刻みのデータ区間を作成しています。
※このデータ区間は次のような範囲を意味します。
| データ区間 | 範囲 |
|---|---|
| 26 | 26cm以下 |
| 28 | 26cmより大きく28cm以下 |
| 30 | 28cmより大きく30cm以下 |
| 32 | 30cmより大きく32cm以下 |
| 34 | 32cmより大きく34cm以下 |
| 36 | 34cmより大きく36cm以下 |
※「次の級」はデータ区間が36よりも大きいもの、すなわち36cmより大きいサンプルの度数を表します。
※棒グラフの隙間を埋めるために次の処理を行います:棒グラフの棒部分を選択 > 左クリック > データ系列の書式設定 > 要素の間隔を0%にする
■Rによる解析例(基本統計量の算出)
library(psych)
dat <- read.csv("neko_1nensei_eng.csv", header=T) #データの読み込み
#データの分布を算出
summary(dat[,2:3])
#基本統計量の算出
describe(dat[,2:3])
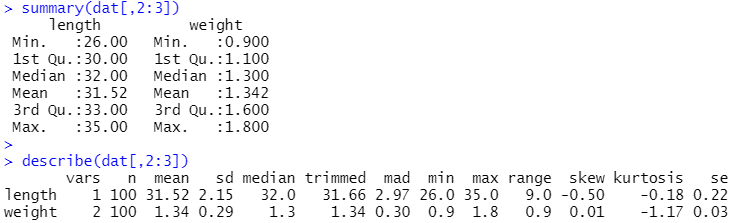
summary関数の出力結果
- min:最小値
- 1st Qu.:第1四分位数
- Median:中央値
- Mean:平均値
- 3st Qu.:第3四分位数
- max:最大値
describe関数の出力結果
- vars:何番目のデータか
- n:データ内のサンプル数
- Mean:平均値
- sd:標準偏差
- Median:中央値
- trimmed:データを小さい順に並べ、小さい側(下位)と大きい側(上位)から指定した個数の値を除き、残ったデータから求める平均値(デフォルトでは上位10%、下位10%のデータが除かれます)
- mad:[中央値からデータの各値を引いた値]の絶対値の中央値(中央絶対偏差)
- min:最小値
- max:最大値
- range:最大値から最小値を引いた値
- skew:歪度
- kurtosis:尖度
- se:標準誤差
■Rによる解析例(ヒストグラムの作成)
#パッケージを使わない場合
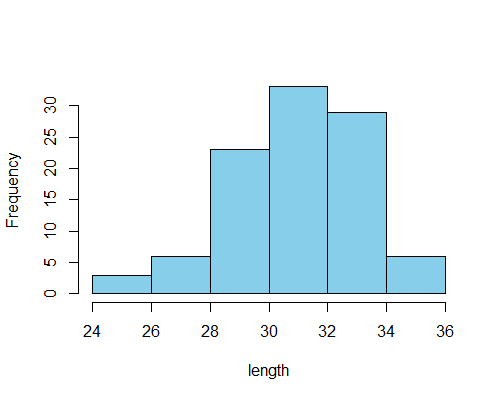
hist(dat[,2], #データを設定
main="", #グラフタイトルの削除
xlab="length", #x軸ラベルの設定
col="skyblue", #ヒストグラムの色を指定
breaks = seq(24, 36, by=2)) #データ区間の指定(24から36まで2刻み)
#ggplot2を使う場合
G <-ggplot(dat, aes(x = length)) + #x軸のデータを設定
geom_histogram(closed = "right", breaks=seq(24, 36, by=2), #ヒストグラムを指定、区間境界の指定(right:~より大きく、~以下)、データ区間の指定(24から36まで2刻み)
fill="skyblue", colour="black") + #ヒストグラムの色を指定、ヒストグラムの輪郭の色を指定
scale_x_continuous(breaks = seq(24, 36, by=2)) + #x軸の目盛を指定(24から36まで2刻み)
theme(panel.grid.major = element_blank(), #背景のgridの削除
panel.grid.minor = element_blank(), #背景のgridの削除
panel.background = element_blank(), #背景色の削除
axis.line=element_line(colour = "black"), #グラフの線の色を指定
axis.ticks=element_line(colour = "black"), #グラフの目盛(ticks)の色を指定
axis.text=element_text(size=14), #グラフの目盛のフォントサイズを指定
axis.title=element_text(size=16)) #グラフのラベルのフォントサイズを指定
plot(G)
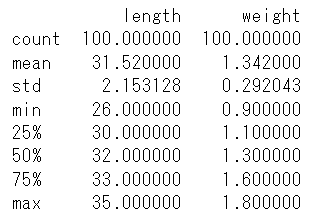
■Pythonによる解析例(基本統計量の算出)
import pandas as pd
dat = pd.read_csv("neko_1nensei_eng.csv")
#基本統計量の算出
print(dat[["length","weight"]].describe())
■Pythonによる解析例(ヒストグラムの作成)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dat = pd.read_csv("neko_1nensei_eng.csv")
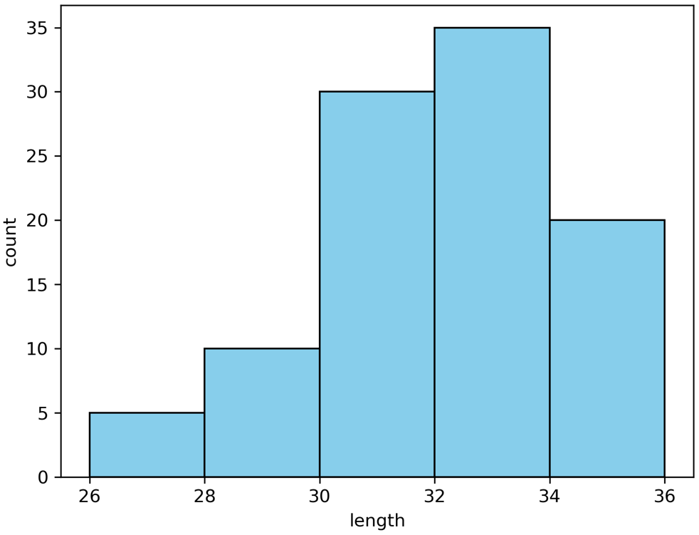
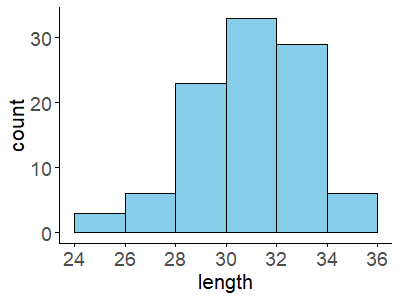
#matplotlibを使う場合
fig, ax = plt.subplots() #グラフの大枠の作成
ax.hist(dat["length"], #ヒストグラムを指定、データを指定
color="skyblue", #ヒストグラムの色を指定
ec="black", #ヒストグラムの輪郭の色を指定(ec:edge colorを意味します)
bins = np.linspace(26, 36, 6)) #データ区間の指定(26から36までを6分割)
ax.set_xlabel("length") #x軸のラベルの設定
ax.set_ylabel("count") #x軸のラベルの設定
plt.show()
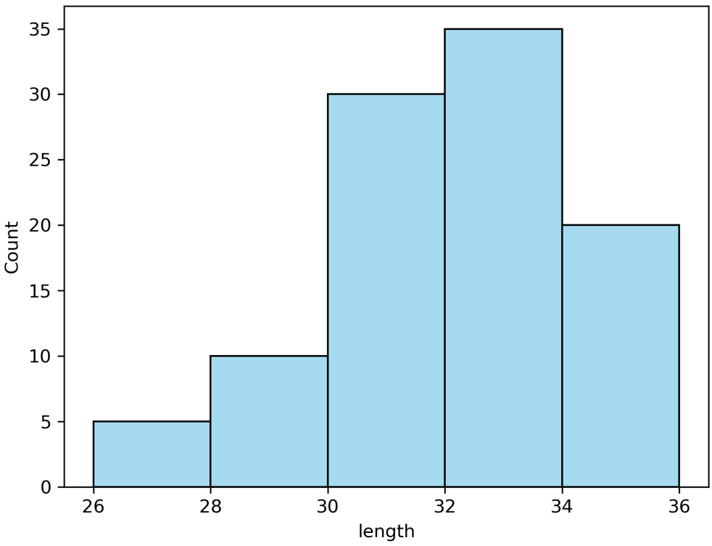
#matplotlib + seabornを使う場合
sns.histplot(x="length", #ヒストグラムを指定、列名を指定
data=dat, #データを指定
color='skyblue', #ヒストグラムの色を指定
bins = np.linspace(26, 36, 6)) #データ区間の指定(26から36までを6分割)
plt.show()